Verwendung von AWS Cloud Services für den Betrieb eines Jira Data Center Clusters
Über Playtech
Playtech is a market leader in the gambling and financial trading industries, traded on the London Stock Exchange Main Market, offering cutting-edge, value added solutions to the industry's leading operators. Since Playtech's inception in 1999, its approach has been centred on the continual development of best-of-breed gaming products and content.
Executive Summary
In the past decade, Atlassian’s issue tracking product Jira has become the most famous software for development teams but also other business areas. As a result, many teams have naturally switched to this software using their own environment, so was also the situation at Playtech. Therefore, the company came to a point where the strategic decision was made to consolidate all existing instances into one big and central Jira Data Center cluster running on Amazon Web Services (AWS). Reducing licensing and operational costs, whilst deploying the enterprise grade versions of the software are key drivers for this transformation. The consolidation of multiple instances also results in a higher demand of processing power and storage, so the ability to scale effectively whilst enabling resilience and redundancy needs to be fulfilled. Even in the best designed system, application failures can not be reduced to zero. So a crucial point in enterprise-scale solutions is self-recovery of the system in case of minor incidents, that end users are not disrupted in their daily business and the operations team can concentrate on critical issues. Putting all the challenges together, leveraging cloud services on AWS definitely promises a stable environment for running applications at the scale of large enterprises.
Customer Challenges
Challenge 1
The consolidation of multiple Jira instances results in a higher demand for processing power and storage space. Due to Jira's customizability it can be difficult to predict the hardware requirements when merging new datasets and growing the user base. Quickly scaling the system based on new requirements is of utmost importance.
Challenge 2
Migrating and maintaining a heavily integrated service without disrupting user workflows requires in-depth testing and quality assurance. Users should never have to deal with downtimes or performance degradation.
Challenge 3
Keeping critical data secure and highly available are the highest priority of any business. As usage of Jira grows so does the need for fault tolerance. Automated recovery solutions should be used where possible to free IT teams from stressful and repetitive tasks.
Partner Solution
The solution was designed based on Atlassian's reference architecture for deployments in AWS (https://aws.amazon.com/quickstart/architecture/jira/). AWS Auto Scaling is used to automatically provision new nodes and disposing of nodes which are unhealthy or unneeded. Nodes are spread across two availability zones in order to increase resilience in case of service disruption of one availability zone.
Jira Data Center Setup
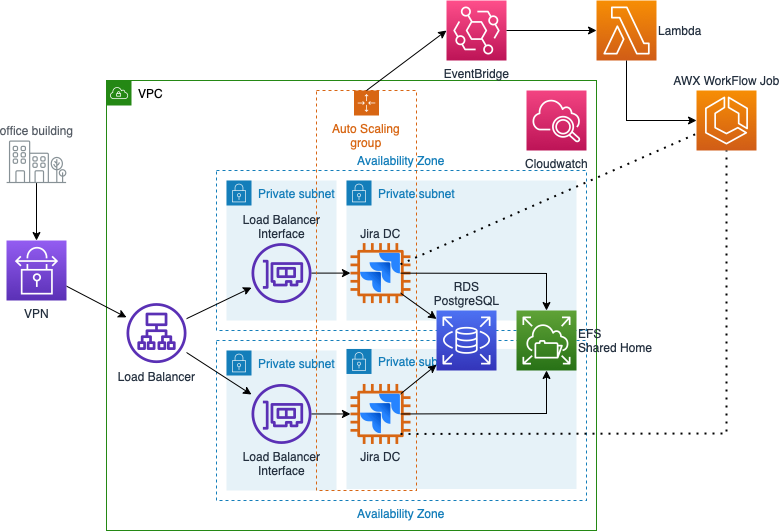
Database: AWS Aurora PostgreSQL deployed across two availability zones provides a highly performant and highly available database solution for the Atlassian Data Center cluster. The Aurora cluster is composed of 1 writer and 1 reader node. As of the time of writing Jira is currently unable to make use of read-only databases, so the reader is only provided for fault tolerance. In case the writer fails, Aurora quickly promotes the reader instance to the writer status.
Storage: The shared file system as required by Atlassian Data Center clusters is hosted on AWS Elastic File System (EFS), which provides a highly-available, cost-effective and maintenance-free storage solution.
Logging and Monitoring: Application logs are stored in AWS CloudWatch Logs using the CloudWatch agent. The agent is installed as part of the AWX workflow job and configured to forward Jira’s log files to CloudWatch. This setup provides the possibility to store the logs in a central place and review them later for troubleshooting purposes in case a failing Jira instance gets terminated by AWS Auto Scaling. Monitoring of the Jira Data Center cluster is done using Prometheus which is also installed as part of an AWX workflow job.
Security and compliance: The entire setup is deployed in a private VPC that is connected to Playtech's corporate network via AWS Transit Gateways. All EBS volumes, S3 buckets, EFS filesystems, and RDS Aurora databases are encrypted via AWS KMS keys by using a combination of AWS-provided and customer-managed keys (CMK). The CMKs are used for backup purposes since they allow for cross-account sharing. All data is encrypted at rest and in transit with TLS-enabled network protocols, as are the backups and their transfer to a separate AWS account. All credentials are stored securely in the AWS Secrets Manager.
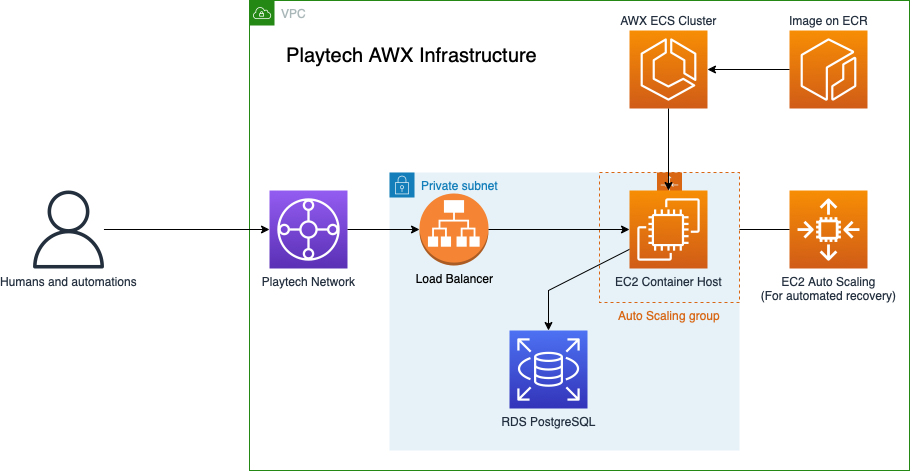
Deployment and orchestration: The use of AWS Auto Scaling requires the use of automated provisioning tools for the EC2 instances. Therefore, AWX has been chosen for solving this problem at Playtech. Each node is provisioned using a workflow template containing the necessary Ansible Playbooks to install and configure Jira Data Center. This job is triggered by an AWS Lambda function which executes a REST API call to AWX. This Lambda is triggered by AWS EventBridge as soon as it receives an “Instance launch successful” event. The orchestration of the AWS infrastructure is done using HashiCorp Terraform. Every AWS resource is created and managed as Terraform code in order to enable quick and easy deployments. The Terraform code as well as the Ansible Playbooks are hosted on AWS CodeCommit. This service has been chosen due to its convenience and reliability, since an unexpected downtime of the git repository would make AWX unusable. Environments are separated using completely different AWS accounts with separate VPCs and all environments are deployed using the same Terraform code. Infrastructure changes are always tested in a development and staging environment before applying them to production.
Results
The provided solution provides Playtech a highly available system with the advantage of self-healing and autoscaling mechanisms. Here are some key improvements which have been achieved:
- The duration for performing a full Jira reindex - which is a quite resource intensive operation - has been decreased by roughly 60% compared to the on-premise solution.
- The autoscaling mechanism of the system provides the major benefit that a rising demand of requests and an increasing amount of data has no negative effect on the daily business of the end users.
- Since the go-live in January 2022, there was no total outage and all minor incidents have been automatically resolved by the self-healing mechanism.
Benefits
Infrastructure as Code (IaC)
- Whole infrastructure for running Jira Data Center can be set up in minutes by the push of a button.
- Configuration changes are made easy by centrally changing just config files.
Isolation of duties using AWS accounts
- Usage of different stages (development, staging and production) for testing new releases or configuration changes.
- Isolated management account for orchestrating and managing the infrastructure, and also including the automation setup.
- Separate account for storing backups in case the primary account gets compromised.
High availability and scaling
- End users are not disrupted by minor system failures.
- Increasing demand is automatically managed by the solution itself.
Security everywhere
- All data in transit and at rest is encrypted.
About the Partner
ByteSource Technology Consulting GmbH based in Vienna is one of the leading experts in the DACH region for AWS, Atlassian, DevOps and agile software development as well as technical consulting. As the largest Atlassian Platinum Partner and AWS Advanced Consulting Partner in Austria, ByteSource proves their expertise in scaling the Atlassian toolset and agile transformation on the innovative Data Center platform. With a focus on DevOps & Cloud Journeys as well as migration and advise, ByteSource realizes large-scale projects up to three times faster than IT companies with conventional approaches.
